Support Vector Machine
The final cetegorical model I tried was an SVM model.
The final cetegorical model I tried was an SVM model.
Github Python Notebook: SVM model
These are the features for my models:
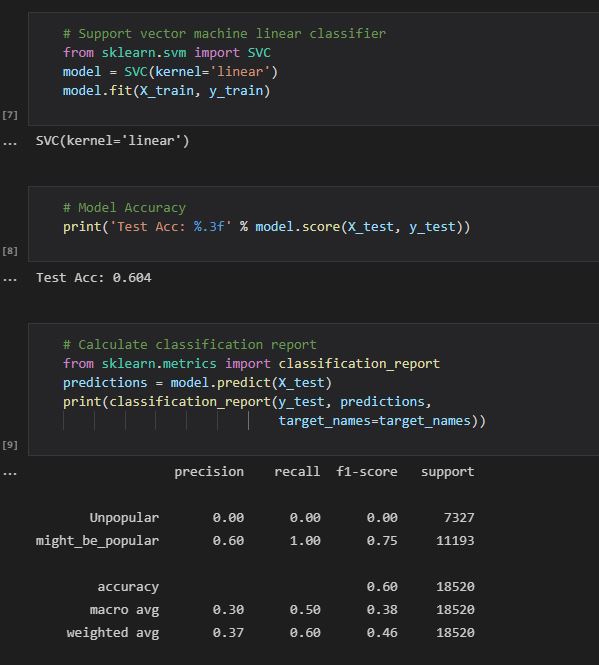
This model proves to be somewhat accurate at predicting whether a song will be popular, but not to a useful degree. Its usefulness at predicting whether a song is unpopular is not useful either