Project Summary

For this project I set out to investigate the musical characteristics of a sample of songs (tracks) from Spotify. The stated aim was to build a reliable model which could take the musical attributes of a track and return its likely popularity on Spotify.
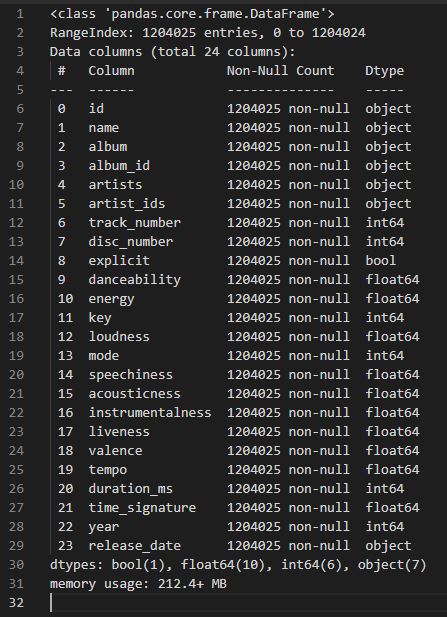
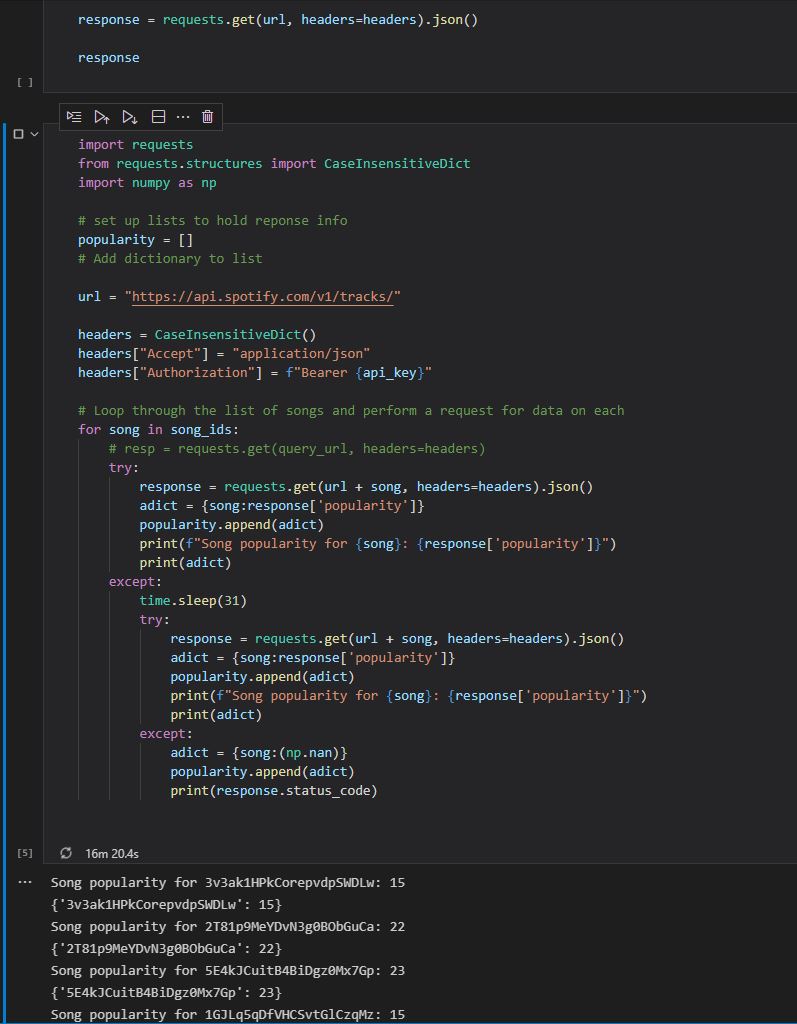
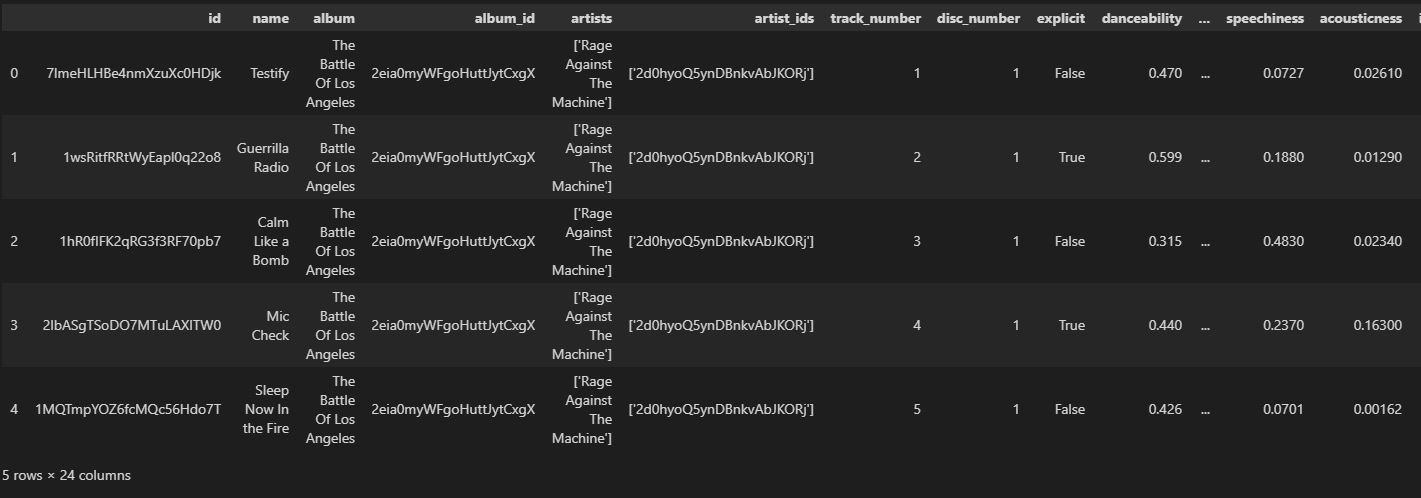
The assembled dataset came from a downloaded CSV file containing song characteristics and was appended with song popularity ratings obtained through the Spotify public API.